What Enterprise Agentic Coding Actually Requires
The Terminal Is the Interface
The first realization, probably by the end of our first pilot phase, was that in an agentic workflow, the delivery systems we’ve relied on for years (Azure DevOps, VS Code, Chrome, Azure Portal) are increasingly operated through agents rather than directly by humans. The terminal is our interface to our agents, and our agents use tools on our behalf.
This isn’t a prediction. It’s how we operate now. Engineers and product owners both work in Claude Code. A developer doesn’t open GitHub to check what work is available. They run /dev-review-queue and Claude Code queries GitHub, validates issue quality, analyzes interdependencies across the queue, and presents the results with a recommendation. A product owner doesn’t open GitHub to create an issue. They run /po-create-work-item and Claude Code interviews them, formats the issue, runs quality validation, and handles the API calls. A developer doesn’t open Chrome DevTools to manually test their implementation. They run /dev-complete and Claude Code operates the browser, validates acceptance criteria, reviews the code, and creates the pull request.
Nobody has to leave the terminal, though they can if they want. The traditional tools still exist and still work. But the workflows were designed so the terminal is the complete experience.
This has a direct consequence for process design: the skill is the user experience. There’s no GitHub UI providing ambient context about what labels mean, what the next step should be, or who to notify. The skill has to provide everything the human needs to make their decision, enforce the process, and handle the tool interactions. That’s why our skills are opinionated and guided rather than thin wrappers around API calls.
I Need to Know Who Owns the Next Step
At any given moment, for any piece of work, someone specific needs to be responsible for moving it forward. Not a team. A person.
This sounds obvious, but traditional SDLC tools are terrible at it. A Jira ticket is “assigned” to someone, but that assignment doesn’t change as the work moves through stages. The developer is assigned during development, but when it moves to UAT, the product owner needs to act. Who updates the assignment? In practice, nobody. You find out something is waiting on you when someone pings you in Slack.
In our system, ownership transfers are enforced by the workflow itself. When a product owner marks an issue as ready, the skill removes their assignment so it appears as unassigned in the engineering queue. When an engineer rejects an issue via /dev-review-queue, the system automatically reassigns it to the product owner who originally marked it ready, with the feedback attached. When /dev-complete creates a pull request, ownership shifts to reviewers.
Nobody has to remember to update an assignment field. The transitions handle it.
Our visibility layer (Signal) consumes these ownership changes as events. When leadership asks “where is the portal project stuck?” the answer is derived from the data: it’s in the Requirements gate, assigned to a specific person, and it’s been there for three days. No status meeting required.
Every Commit Traces to a Tracked Requirement
In a regulated industry, “someone pushed code to production” is not an acceptable level of traceability. We need to know: what requirement drove this change? Who approved it? What acceptance criteria were defined? Did they pass?
Our branch naming convention enforces this mechanically. When an engineer runs /dev-work #42, the skill creates a branch named feature/issue-42-csv-export and links it to the issue in GitHub. Every commit on that branch is traceable to issue #42. The pull request created by /dev-complete includes a validation report documenting which acceptance criteria were checked, how they were validated (code review, automated tests, functional verification), and whether they passed.
A work item reaches the “Released” gate only when a production deployment succeeds, not when someone closes a ticket. The deployment event ties back to the PR, which ties to the branch, which ties to the issue, which contains the original requirement and acceptance criteria. The full chain is automated.
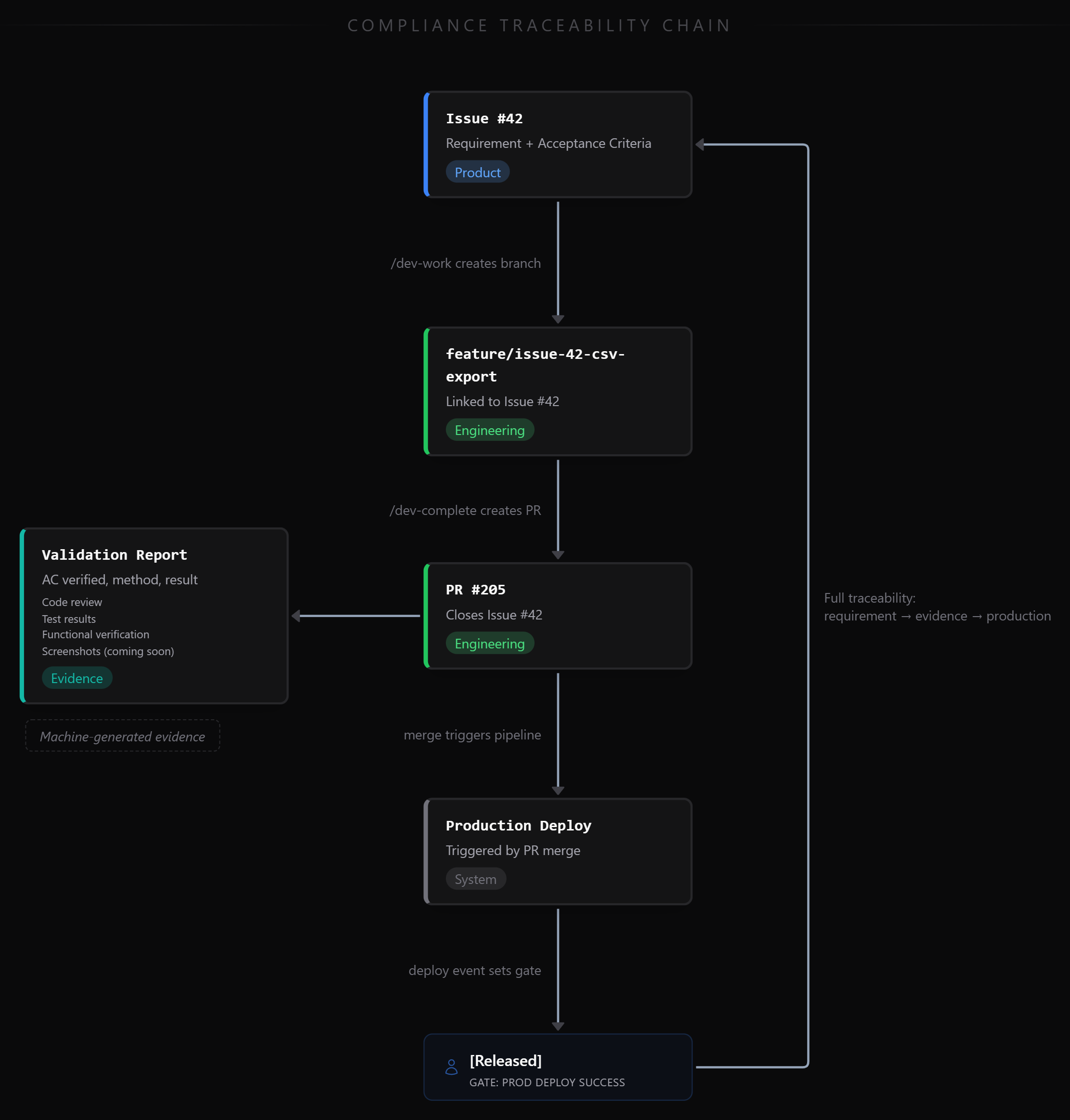
One distinction worth making explicit: issue closure and release tracking are different concepts. An issue closes when its PR merges, because the acceptance criteria have been verified and the work is complete. The Released gate is set later, when the code actually deploys to production. This disentangles “I finished the work” from “what is the release plan.” For some products, release might be a trivial continuous deployment push. For others, it might be a two-week release cycle tied to third-party features and legacy database changes. The SDLC doesn’t prescribe the release cadence. It tracks when the code reaches production, however it gets there.
This isn’t just compliance theater. The validation report in every pull request provides documented signoff of every acceptance criterion: what was checked, how it was verified, and the result. Each report includes acceptance criteria parsed from the issue, links to automated test runs, notes from functional verification, and any exceptions with rationale. When something breaks in production, the first question is “what changed?” With this traceability, the answer is a query, not an investigation. And when an auditor asks “how do you know this feature was tested before release?” the answer is a link to the PR with machine-generated verification evidence attached.
Gates Must Be Real
Every SDLC has gates on paper. The question is whether those gates actually prevent work from advancing when it shouldn’t.
In most organizations, gates are advisory. A Jira board has columns, but nothing stops you from dragging a card to “Done” without a review. A pull request template has checkboxes, but nothing enforces that they’re answered honestly.
Our system uses six gates (Intake → Requirements → Design → Development → UAT → Released), and transitions are triggered by specific events, not manual status updates. An issue enters Development when it receives the accepted label. It reaches Released when production deployment succeeds, not when someone closes a ticket.
The skills enforce their own prerequisites. /dev-work checks for the accepted label and won’t proceed without it. If the issue has needs-clarification instead, the skill tells the engineer to check with Product rather than letting them start building against unclear requirements. /dev-complete parses acceptance criteria from the issue and validates each one before creating a PR.
The human gates (architecture approval, design review, UAT signoff) remain human because that’s where judgment matters. The automated enforcement between them handles the mechanical compliance that humans are bad at remembering.
A question we get asked: what about access control? Who can invoke which skills? The answer is straightforward. Any engineer in the agentic development group can run any skill. Someone could /propose-architecture without authorization and submit it for review. The architecture team would review it, and either approve or reject it on merit. They could claim it was approved and run /request-infrastructure. The DevOps team would review the request and not provision anything without verifying approval. At every step, human gates catch unauthorized work. And if someone somehow pushed through all the gates dishonestly, all they’ve accomplished is creating a thorough, timestamped, documented trail of exactly what they did. The system doesn’t grant privileged access to infrastructure, production environments, or sensitive systems. It creates auditable artifacts that flow through human checkpoints.
The Process Must Adapt to Different Work Types
Not all work needs the same rigor. A new initiative with regulatory implications needs architecture review, infrastructure provisioning, and formal UAT. A bug fix needs reproduction steps, a fix, and verification. Treating them identically either slows down simple work or under-governs complex work.
The fundamental split in our system is between issues (product-oriented) and tasks (engineering-oriented). They use different templates, different validation criteria, and different paths through the gates.
Issues are typically created by product owners via /po-create-work-item. They require acceptance by an engineer before development can start, and they specify work through acceptance criteria in Given/When/Then format. Issues come in three types:
- Features require a summary, acceptance criteria, and the full gate sequence. The quality validator flags vague language and checks that each criterion is independently testable.
- Bugs require steps to reproduce, expected behavior, and actual behavior. Same gates, but validation is structured around reproduction.
- Defects (found during UAT) link to their parent issue and skip directly to Development, since the parent feature already cleared Intake, Requirements, and Design.
Tasks are created by engineers via /dev-create-task for tech debt, infrastructure, maintenance, and enablement work. They bypass product owner review entirely, receiving ready and accepted labels immediately. Instead of acceptance criteria, tasks specify work through a Definition of Done checklist. Engineers own these end to end.
The skills adjust their behavior based on type. /dev-complete parses Given/When/Then for features, Steps to Reproduce for bugs, and Definition of Done for tasks. The same command, different validation logic. The engineer doesn’t have to think about which process applies.
Domain Teams Must Own Their Own Standards
In most mid-size enterprises, architecture and DevOps are either a bottleneck or they’re ignored. Centralize the expertise and every project waits in a queue for review. Distribute it and you lose consistency, with each team making its own technology choices and provisioning decisions. The center of excellence model sounds good in theory, but it’s never really scaled in organizations like ours because the experts can only be in so many rooms at once.
Agents break that tradeoff. The expertise stays centralized, owned by the people who know it best. But agents distribute it at scale, applying those standards consistently across every project without the experts being personally involved in every decision.
We implemented this by letting each domain team maintain their own standards as knowledge bases that the skills fetch at runtime. The architecture team maintains their technology options, review instructions, and proposal template in their own repository. The DevOps team maintains their infrastructure catalog, provisioning instructions, and request template in theirs.
When an engineer runs /propose-architecture, the skill fetches the architecture team’s current standards and uses them to guide the interview and generate the proposal. If the architecture team updates their standards (adds a new approved database option, changes their template), every subsequent invocation picks up the changes automatically. The standards are versioned in code and reviewed like any other change. No central process document to update. No wiki page that’s six months stale.
This is the center of excellence model, scaled by agents. The architecture team and DevOps team define the standards once. The agents apply them everywhere. The human experts review the outputs and make judgment calls on exceptions. Their expertise is leveraged across every project in the organization, not bottlenecked by their calendar availability.
What’s Coming Next
The next post walks through the Initiative Planning track in detail: how /plan-initiative produces a structured summary from raw input, how /propose-architecture consumes it to generate a technology proposal, and how /request-infrastructure turns an approved architecture into a DevOps request. The full semantic contract chain, with real artifacts.