Initiative Planning: From Idea to Infrastructure
The Semantic Contract Chain
In a traditional enterprise process, the path from offsite notes to an engineer writing code passes through multiple document translations, each losing fidelity, each introducing delay. Our approach eliminates the translations. Each skill produces a structured document that the next skill can consume directly. The documents are contracts: specific enough that downstream skills can operate on them, standard enough that the pattern is repeatable across any initiative.
This chain wasn’t designed on a whiteboard. It emerged from actually trying to take a project from zero to a running application through the new process. We had the incremental development track working: product owners could create individual issues, engineers could review and build them. But going from a prototype to a properly architected application by creating issues one at a time was a struggle. There was no structured path from “here’s an idea” to “here’s an approved architecture with infrastructure provisioned and foundation work planned.” Every gap we hit became a skill: we needed architecture approval before starting, so /propose-architecture was built. We needed infrastructure requested before we needed it, so /request-infrastructure was built. We needed foundation tasks planned rather than improvised, so /derive-foundation-tasks was built. The chain exists because we lived the problems it solves.
The chain looks like this:

Product and Engineering tracks run in parallel after the Initiative Summary exists. The architecture track needs approval before infrastructure and foundation tasks can proceed, but product can start decomposing features immediately.
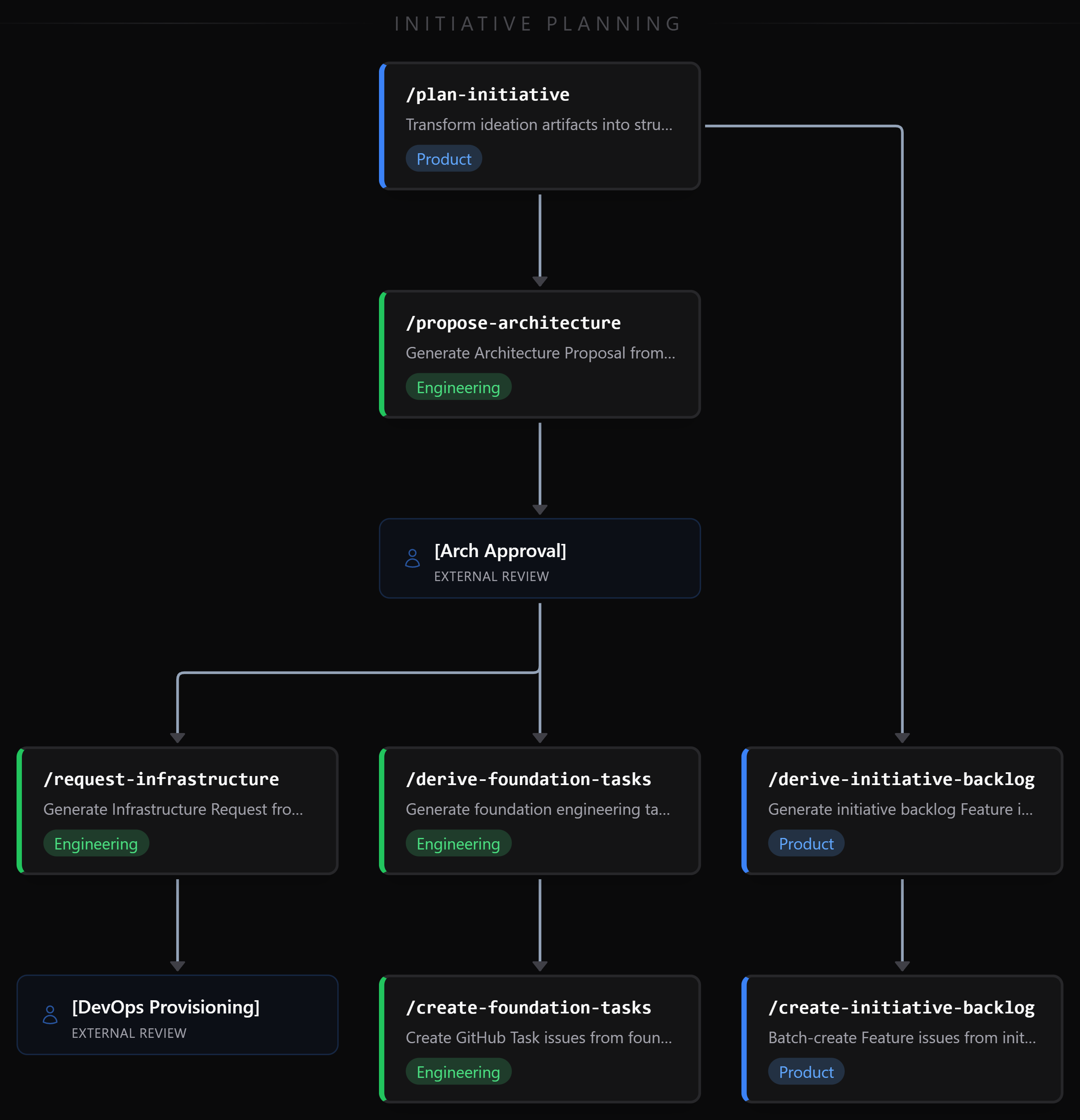
Step 1: Plan the Initiative
/plan-initiative accepts whatever raw material exists: offsite notes, Slack threads, executive requests, prototype code, Figma designs, interview transcripts. The skill reads the input, identifies what’s present and what’s missing, then conducts a guided interview to fill the gaps.
The skill is governed by a philosophy document that defines what an Initiative Summary is and isn’t. It’s a product document, not an engineering document. It captures business problems, user workflows, capabilities, success criteria, and scope boundaries. It does not capture system architecture, API contracts, or database schemas. That distinction matters because it keeps Product focused on what users need, and lets Engineering make technical decisions with the full business context in front of them.
The skill’s anti-patterns are explicit. The first one listed: “Generating 43 GitHub issues while ‘Who is the primary user?’ is still unclear.” If the initiative’s fundamental questions aren’t resolved, creating downstream work is waste.
Blocker Surfacing
This is where the semantic guardrail concept from Post 1 becomes concrete. Before generating any output, the skill analyzes the input for unresolved questions that would derail downstream work. Not theoretical risks. Specific questions where different answers would lead to different implementations.
For each blocker, the skill presents it to the user with context:
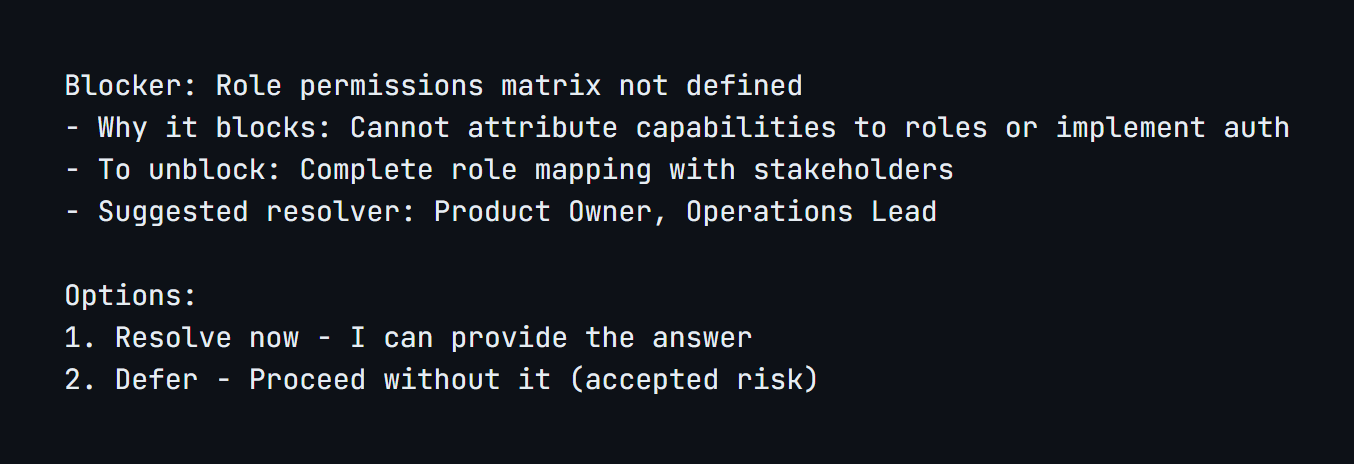
If the user resolves it, the answer gets incorporated into the document. If they defer, it’s recorded with the acknowledged risk. Either way, the decision is explicit.
Capability Refinement
The skill also enforces a specific level of granularity for capabilities. Too vague (“track loan status”) and engineering can’t scope the work. Too detailed (“Given I am logged in, When I click Status, Then I see…”) and you’re writing acceptance criteria that belong in individual feature tickets.
The target is “specific enough to visualize, not so detailed it becomes acceptance criteria.” The skill probes to get there: “What specific information does the user see? What needs to happen behind the scenes? Does data need to sync anywhere?”
The Output
The Initiative Summary has a fixed nine-section structure: Overview, Glossary, User Roles and Workflows, Capabilities, Integrations, Business Constraints, Scope and Boundaries, Blockers, and Next Steps. Every section is required. If a section has no content, it says “None identified” rather than being omitted.
This consistency matters because the downstream skills know exactly what to expect. /propose-architecture knows where to find integrations. /derive-initiative-backlog knows where to find capabilities. The structure IS the contract.
Step 2: Propose Architecture
Once the Initiative Summary exists, an engineer runs /propose-architecture with it as input. Here’s where the distributed ownership model comes in.
The skill doesn’t contain architecture standards. It fetches them at runtime from a separate repository owned by the architecture team:
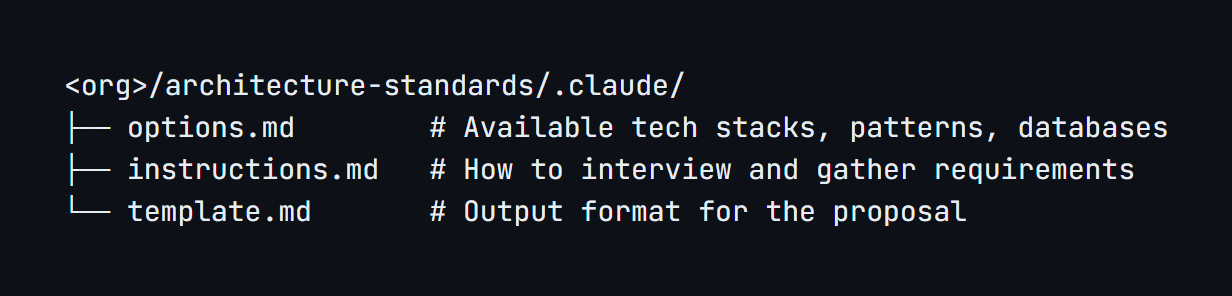
The architecture team maintains their own options (approved databases, authentication patterns, hosting choices), their own interview questions, and their own output template. When they update their standards (add a new approved database, change their template format), every subsequent /propose-architecture invocation picks up the changes automatically. No central process document to update. No wiki page that’s six months stale.
The skill reads the Initiative Summary, fetches the architecture knowledge base, interviews the engineer about technology preferences that aren’t already decided, and generates an Architecture Proposal. One practical detail: the skill verifies that selected packages are using current versions by checking npm, NuGet, or PyPI registries live, guarding against LLM knowledge cutoffs that would otherwise pin your new project to last year’s packages.
The architecture and DevOps teams work hand in hand here. The architecture team’s approved options (technology stacks, authentication patterns, database choices) are deliberately aligned with what DevOps already has tooling to support: deployment pipelines, disaster recovery, monitoring, resiliency patterns. When a project stays within the approved reference architecture, the downstream infrastructure request is practically a known quantity. DevOps isn’t scrambling to support an unfamiliar stack. They’re provisioning a well-understood configuration from existing patterns. The whole chain is pre-integrated.
The proposal must be detailed enough that the architecture team can approve, reject, or modify it, and that foundation tasks and infrastructure requests can be derived from it.
The Human Gate
Architecture approval is a human decision. The skill generates the document. A human architect reviews it and approves, rejects, or requests changes. This is intentional. Technology selection, integration patterns, and architectural trade-offs require judgment that the AI shouldn’t make autonomously.
The critical point is that this gate is enforced, not advisory. /request-infrastructure and /derive-foundation-tasks both check for approval status and won’t proceed without it. The system won’t advance work into Development or generate downstream artifacts until architecture is approved and infrastructure requests are submitted.
Every enterprise engineering leader has lived the alternative. An engineer gets a “build this app” request and nobody defines how you get from zero to a running application with the right architecture to support the planned features. So the engineer makes architecture decisions by default, builds it on their laptop, and then asks architecture to rubber-stamp choices that are already baked in. Or they build the whole thing locally and then tell DevOps they need four environments tomorrow for a committed release date.
Our chain prevents both patterns structurally. The architecture review happens before any code exists, when changing direction is cheap. The infrastructure request happens before anyone needs environments, when DevOps has time to provision properly. These aren’t process aspirations. They’re prerequisites enforced by the skills themselves.
Once approved, the Architecture Proposal becomes the binding input for two parallel activities.
Step 3: Request Infrastructure
/request-infrastructure takes the approved Architecture Proposal and generates an Infrastructure Request for DevOps. Like the architecture skill, it fetches its knowledge base from a separate repository owned by the DevOps team:
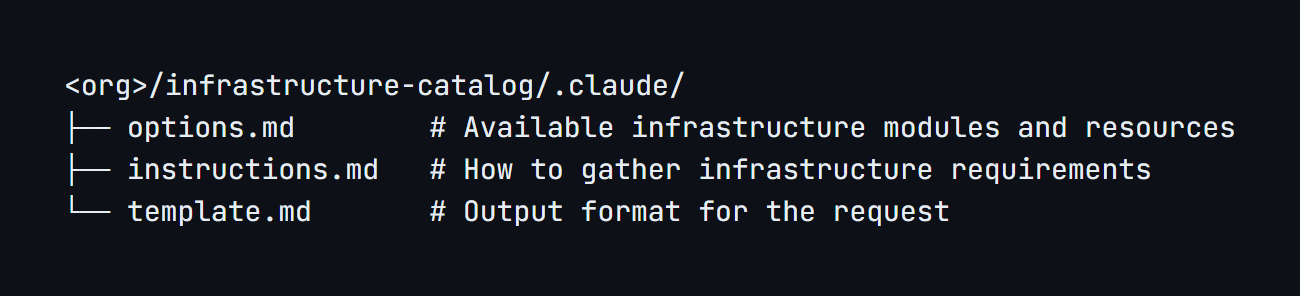
Same pattern: DevOps owns their process, the skill facilitates it. The skill interviews the engineer about environments needed, scale expectations, and timeline, then generates the request using DevOps’s own template.
To be clear: the architecture and DevOps teams are also agent-enabled. They have their own specialized processes that these artifacts feed into. The human gates aren’t here because the AI can’t write Terraform or GitHub Actions. Claude Code can absolutely generate infrastructure-as-code. DevOps is engaged because they own the integrated environments from a controls perspective: security policies, disaster recovery, monitoring, resiliency. That’s a governance function, not a capability limitation. The architecture review exists for the same reason. The AI could generate an architecture proposal without human input. But technology selection for a regulated enterprise involves judgment about security, supportability, vendor risk, and organizational expertise that should be made by humans who are accountable for those decisions.
One critical guardrail: the skill will not invent details that aren’t in the Architecture Proposal. If the proposal says “Messaging: Azure Service Bus” without specifying queue names, the skill doesn’t guess. It marks it as TBD and adds it to the open questions section. DevOps needs accurate information to provision correctly. Invented details become false requirements.
Step 4: Derive and Create Foundation Tasks
/derive-foundation-tasks addresses the gap between “architecture approved” and “engineers can start building features.” It reads the approved Architecture Proposal and generates a structured markdown file containing every engineering task needed to bootstrap the application: project scaffold, authentication, data access, observability, and integration clients. Each task includes a summary, rationale, definition of done, technical context derived from the proposal’s technology selections, and dependency relationships. No engineer has to figure out from scratch how to get from an empty repo to a running application that matches the approved architecture.
The skill explicitly excludes infrastructure work (CI/CD, Terraform, environment provisioning) because that’s owned by /request-infrastructure and the DevOps team. Foundation tasks are application code only.
This produces a plan, not issues. The engineer reviews the file, adjusts priorities, edits definitions of done, and adds any missing context. Then /create-foundation-tasks reads the file and batch-creates GitHub Task issues, applying labels (ready, accepted, priority:critical) and linking dependencies by issue number.
The two-step pattern (plan file → review → create issues) exists because batch-creating issues from AI-generated content without human review is exactly the anti-pattern the whole system is designed to prevent.
What This Looks Like End to End
The full path, compressed: product owner runs /plan-initiative with raw input, resolves blockers, produces an Initiative Summary. Engineer runs /propose-architecture, architecture team approves. In parallel: /request-infrastructure produces a DevOps request, /derive-foundation-tasks generates and creates bootstrap issues.
The interesting transition is what happens next. While the engineering track was getting architecture approved and infrastructure requested, product was decomposing the Initiative Summary into feature issues via /po-create-work-item. By the time an engineer runs /dev-work #101 on the first foundation task, the product backlog is already forming alongside them. The two tracks converge: foundation tasks give engineers a properly architected application to build in, while product issues give them the features to build.
No document translations. No context lost between stages. The documents carry the context, and the skills enforce the quality. When people do connect (a quick call to discuss architecture trade-offs, a sync to clarify requirements), the conversation is about substance, not logistics.
What This Changes About Which Work Gets Done
There’s a less obvious consequence of making the initiative planning process fast and low-overhead. In our previous world, spinning up a properly governed project had a fixed cost in meetings, documents, and coordination that was the same whether you were building a platform for 2,000 loan officers or a tool for a five-person funding team. The big initiatives always justified that cost. The small ones never did.
We always had time to build tools for our large sales organization. But our funding team? Our rate sheet team? They were stuck with Excel because the overhead of doing it right exceeded the value of doing it at all at their scale.
That calculus has changed. Running /plan-initiative through /create-foundation-tasks takes hours, not weeks. Architecture review and infrastructure provisioning follow established patterns. A small team that was previously too small to justify a development project can now get purpose-built tooling through the same governed process as a major strategic initiative, just with a smaller scope. The same traceability and controls apply. The process scales down as well as up.
Completing the Product Track
The chain diagram above shows /derive-initiative-backlog on the product side, mirroring the tasks path. This skill reads the Initiative Summary and generates a batch of properly formatted feature issues with concrete acceptance criteria, decomposing capabilities into individual work items. /create-initiative-backlog then batch-creates the GitHub issues in parallel, applying labels and marking them ready for engineering review. Together they wrap /po-create-work-item the same way /create-foundation-tasks wraps /dev-create-task, giving product owners a path from Initiative Summary to a full backlog in one pass.
What’s Coming Next
The next post covers the other side of the workflow: the daily development cycle. How product owners and engineers interact through the queue system, how work moves from accepted to pull request, and how the accountability loop keeps people connected without the overhead.