Building an Agentic SDLC in a Regulated Enterprise
How We Got Here
In September 2025, we launched an invite-only AI development pilot with a small group of senior practitioners. We worked with leads across the organization to select for the most capable and engaged candidates. Nobody outside the program changed their development process. There was no mass allocation of “here are coding agents, good luck.”
The program ran in four phases, each with a deliberate mission. Phase 1 proved the tools could deliver production software: we shipped an enterprise AI chat platform (LibreChat, OpenRouter, custom MCP-based RAG agents for our loan products), a document classification engine that hit production in three weeks, and a partner portal built by a single engineer that previous estimates ranged up to six months for a traditional team. That engineer later trained two others across subsequent phases, handed the project off, and moved on. Phase 2 doubled participation, figured out training methodologies through mentor pairing, and expanded from solo practitioners to small teams. Phase 3 pushed into brownfield codebases and IT operations, handing ownership back so participants could bring skills to their regular teams.
By the end of Phase 3, two things were clear. First, the tools worked. Second, as development velocity increased, the time spent waiting on requirements, clarifications, and scope decisions became the dominant factor in delivery speed. These gaps had always existed, but when implementation took weeks, they were hidden inside the overall timeline. When implementation started taking hours, they were impossible to ignore. On one greenfield project, median cycle time (issue accepted to PR ready) dropped from 55 hours to 1.3 hours over two weeks, not because the AI got faster, but because the team got better at defining what they wanted.
That insight drove everything we built next: implementation is no longer the constraint. Requirements clarity, organizational coordination, and process discipline are.
Starting From First Principles
I knew from the start we’d need a new process, but I intentionally let it emerge from experience rather than designing it in a committee. By Phase 4, we had enough collective pain to know what the process needed to provide.
Rather than starting from any team’s existing workflow, we asked a fundamental question: what does an enterprise SDLC actually need to emit? We used the development of our own delivery visibility dashboard, Signal, to force these requirements into concrete form. Signal needed to answer “what’s in flight, where is it stuck, who owns the next step” without anyone manually updating a status field. Building it meant defining the signals:
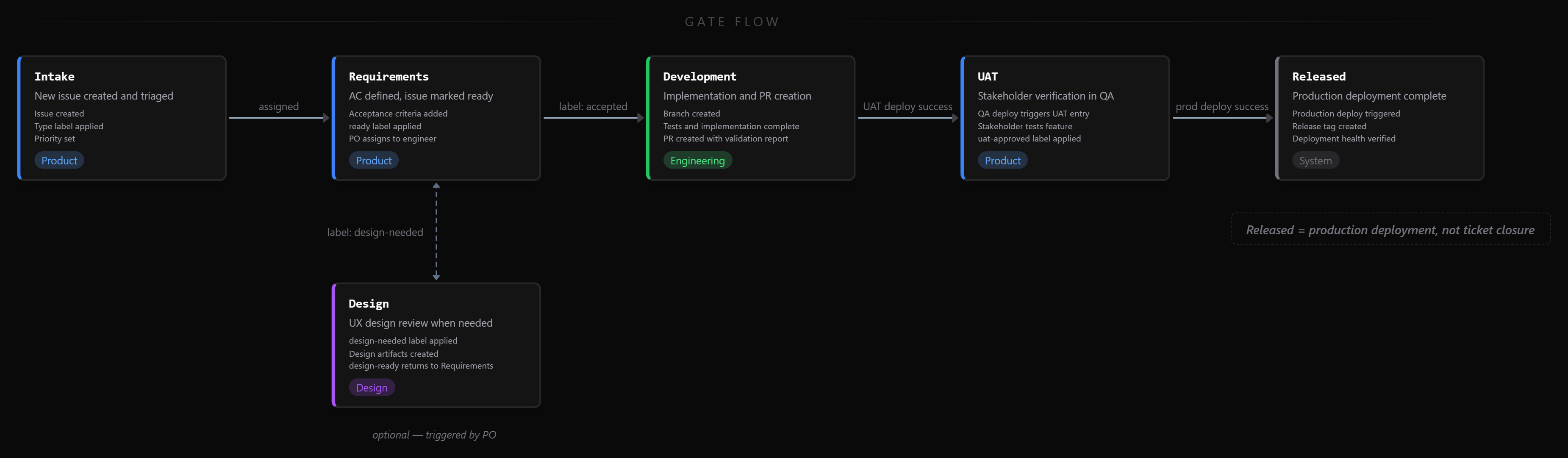
Gates: Intake → Requirements → Design → Development → UAT → Released. Transitions triggered by events (label changes, assignments, deployments), not manual status updates. A work item reaches “Released” when it deploys to production, not when someone closes a ticket.
Signals: Current owner, current gate, due date, estimated completion, health status. Derived automatically from the event stream.
Principle: Delivery is a three-way agreement between Product, Design, and Engineering. The process enforces accountability, not just documents it.
These aren’t AI-specific requirements. They’re the requirements every enterprise technology leader has. The difference is we designed a system to meet them with AI as the primary interface.
Skills as Semantic Guardrails
The core of the system is a Claude Code plugin built on Anthropic’s skills framework. When we started, skills didn’t exist yet, so we built our workflows as custom slash commands, Claude Code’s original mechanism for reusable prompts. When Anthropic introduced skills as a more capable successor (with structured metadata, supporting files, and automatic invocation), we migrated. Skills let us package opinionated workflows that Claude Code knows when to invoke, with each one encoding a specific stage in the development lifecycle. They use GitHub Enterprise as the underlying system of record.
What makes this approach fundamentally different from traditional process automation is that skills are semantic guardrails, not binary gates. A required field in Jira is either filled or empty. A CI check passes or fails. There’s no judgment. Skills negotiate. When a technical product owner dumps implementation details into what should be a business document, the skill pushes back: that’s an engineering decision, describe the business outcome instead. When a casual product owner gives vague one-liners, the skill probes deeper: what specific information does the user see? Does data need to sync anywhere? The same skill adapts to different users while enforcing the same quality bar on outputs.
When a skill identifies a question that would derail downstream work, it doesn’t just fail. It surfaces the blocker, explains why it matters, suggests who can resolve it, and offers to defer with acknowledged risk. When it encounters issues it can handle directly (a documentation gap, a formatting problem), it handles them and reports what it did. When it encounters issues that need human judgment (missing test coverage, architectural questions), it stops and explains what’s needed. That’s process enforcement that people work with instead of around.
Documents Are the Process
The critical design principle: the output of one stage is a structured document that becomes the binding input for the next. We call this the semantic contract chain. An Initiative Summary isn’t just documentation. It’s the contract that Architecture and Product both consume. An Architecture Proposal isn’t just a design doc. It’s the contract DevOps and Engineering consume.
Human gates sit at the judgment points (architecture approval, design review, UAT). AI handles the translation, formatting, decomposition, and enforcement between them. The documents carry the context so every handoff is a structured input, not a lossy translation. Each gate approval is tied to a concrete artifact, not tribal knowledge.
This principle drives both tracks of the system.
Two Tracks
Initiative Planning handles the path from a rough idea to structured, implementable work. A product owner feeds raw material (offsite notes, prototypes, Slack threads, Figma designs) into /plan-initiative, which surfaces blockers and produces a structured Initiative Summary. That document feeds architecture review and feature decomposition in parallel. After architecture approval, the approved proposal feeds infrastructure provisioning and foundation task planning. Each stage consumes the previous stage’s output as its structured input. Post 3 in this series walks through this chain in detail.
Incremental Development handles the daily cycle. Product owners create well-formed issues. Engineers review, accept or reject with feedback. Rejections route back automatically with specific comments. Accepted work flows through branch setup, test planning, implementation, validation (code review, automated tests, functional verification), documentation updates, and PR creation with a comprehensive validation report. Post 4 covers this track end to end.
Both tracks share the same gates, the same event-driven status tracking, and the same principle: automate the logistics so humans can focus on substance.
Where We Are Now
The pilot program has expanded through four phases, each roughly doubling participation, now spanning software engineering, IT operations, DevOps, infrastructure, and security teams. Alongside the development methodology work, our enterprise AI platform (chat, knowledge agents, domain-specific tools) is available organization-wide. The methodology is where we’re being deliberate about rollout. The broader AI adoption touches everyone.
This is a post-Agile workflow. We don’t sprint. We don’t estimate in points. Work flows continuously through defined gates with clear ownership at each stage. Traditional velocity metrics don’t apply when implementation complexity is no longer the dominant factor in delivery time. What matters is commitment reliability: did we ship what we said we’d ship, by the date we committed to.
All new projects must use the new flow. We’ve begun migrating legacy projects from Azure DevOps to GitHub Enterprise. The tooling includes a training site with an interactive workflow simulation, and Signal providing real-time visibility without manual status reporting.
We also have honest gaps. The outer loop connecting business intake to requirements across repositories isn’t finished yet. A single business request might spawn issues across multiple codebases, and understanding when that request has been fully satisfied is non-trivial. We have a design but haven’t shipped it. Brownfield is harder to measure than greenfield, and most of our codebase is brownfield. Testing methodology for AI-generated code has come a long way but is still evolving. We’re five months in, not five years.
What’s Coming in This Series
- This post: The system overview
- What enterprise agentic coding actually requires: The constraints a regulated industry imposes
- Initiative planning: from idea to infrastructure: The semantic contract chain in detail
- The daily development cycle: How product owners and engineers interact day-to-day
- Results and honest assessment: What the data shows, what’s working, what isn’t
If you’re an engineering leader trying to figure out how to move from “developers using AI” to “an organization operating with AI,” I hope this is useful. We’ve been looking for this content ourselves and couldn’t find it, so we’re writing it.